iOS MachineLearning 系列(20)—— 训练生成CoreML模型
iOS MachineLearning 系列(20)—— 训练生成CoreML模型
本系列前面的文章详细的介绍了在iOS中与AI能力相关的API的使用,也介绍了如何使用训练好的CoreML模型来实现更强大的AI能力。然而,无论是成熟的API提供的能力,还是各种各样的三方模型,有时候都并不能满足某一领域内的定制化需求。当我们拥有很多的课训练数据,且需要定制化的AI能力时,其实就可以自己训练生成CoreML模型,将此定制化的模型应用到工程中去。
如果安装了Xcode开发工具,会自动安装Create ML工具,在Xcode的Develop Tool选项中,可以找到此工具:

Create ML工具默认提供了许多模型训练模板,如图片分析类的,文本分析类的,音频分析类的等,如下图所示:
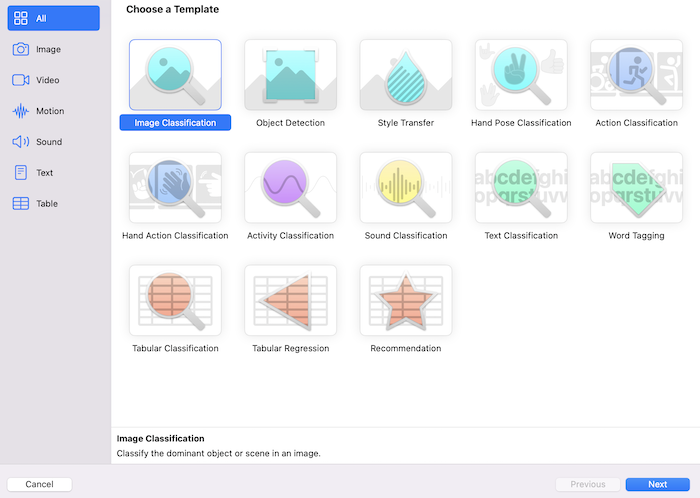
每种模板对应的训练方式不同,我们可以根据需求来选择要使用的模板。
1 - 自己训练一个图片分类模型
图片分类属于图片识别类的模型,当我们输入一个图像时,其会自动分析并进行标签分类。要训练模型,首先我们需要有一定数量的已经分类好的图片。本示例中,我们使用火影忍者中的鸣人和佐助的图片作为素材来进行训练,实现一个能够自动识别鸣人或佐助的模型。
首先新建一个Create ML工程,这里我们将名称设置为YHImageClassifier。模板使用Image Classification。基础信息如下图所示:
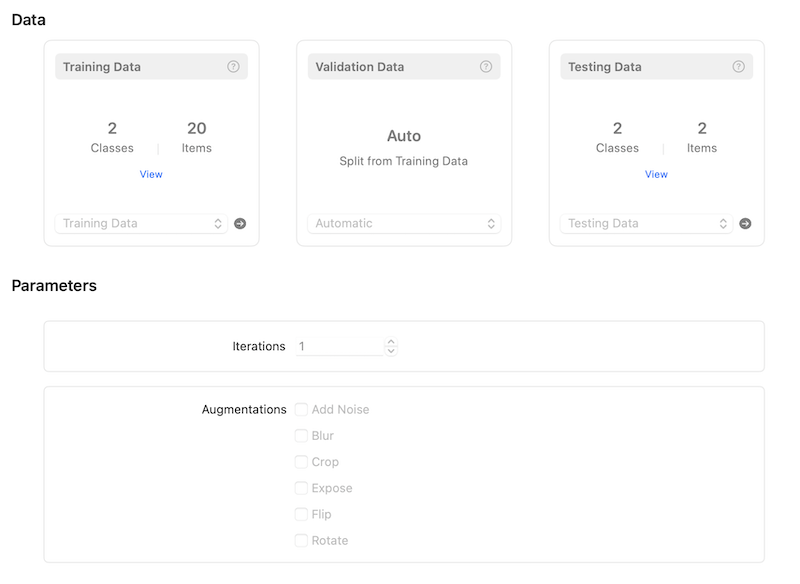
之后我们需要准备训练数据和测试数据,训练数据需要每个类别至少10张图片,图片的格式可以是JPEG或PNG,尺寸无需特别规定,尽量使用299*299尺寸的图片,数据集的数据越多,训练出的模型将越健壮和强大,每张素材图片应尽量的从不同的角度和光照方向来描述事物,并且需要注意,每个类别的素材数量应尽量保持平衡。这里为了演示方便,我们直接使用10张鸣人的图片和10张佐助的图片来作为训练素材,将他们按照标签分类放入对应的文件夹中,如下:

其中,Training Data文件夹中有两个子文件夹,分别对应鸣人和佐助两个标签,鸣人和佐助这两个子文件夹中各有10张分类好的图片。Testing Data文件夹中结构与Training Data中的一致,只是每个子文件夹中只有一张用来测试的图片,且测试的图片不在训练集中。使用测试数据可以快速的检查我们的训练结果,如果我们有非常大量的训练数据,则可以考虑将其中的20%用来作为测试数据来进行模型可用性的评估,这里同样为了演示方便,我们每个标签只选择一张图片作为测试数据。
之后,将Training Data文件夹拖入到工程的Training Data项中,Testing Data文件夹拖入到工程的Testing Data项中,我们也可以对一些训练参数进行设置,如迭代次数,是否对图片增加一些处理等,这里我们选择迭代次数为1,不选择任何额外参数,如下:
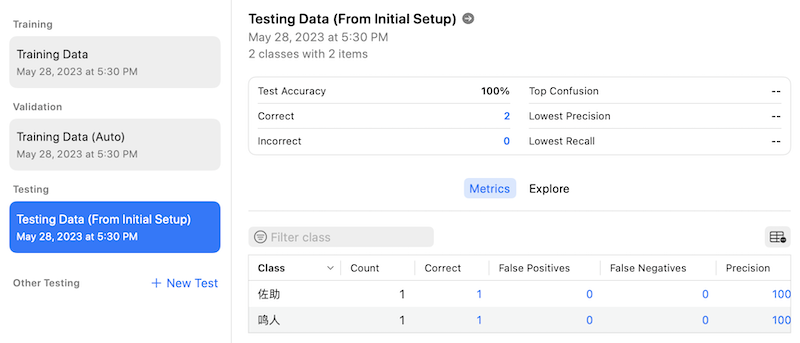
之后点击Train按钮来进行训练,因为我们的输入数据很少,训练会非常快,训练按成后,会自动使用测试数据进行测试,本示例的测试结果如下图所示:
如果测试的结果能够让我们满意,则可以将此模型导出,如下所示:
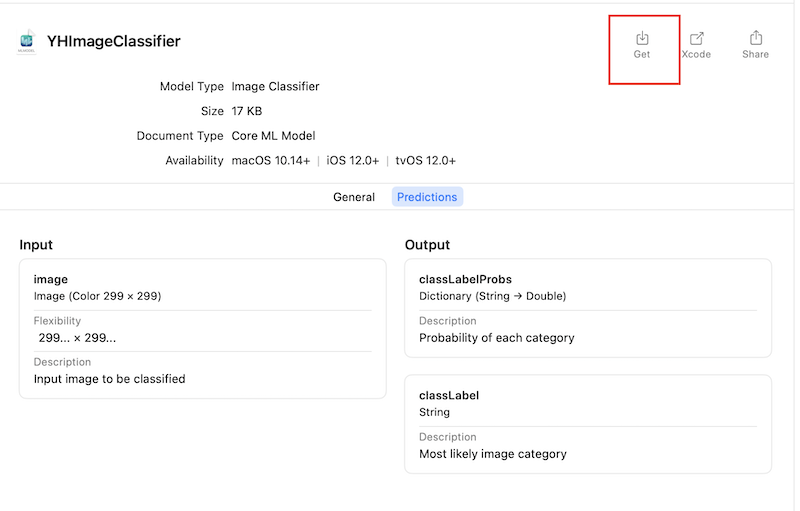
可以看到,此模型的大小只有17k,通过Create ML,训练出一个生产可用的CoreML模型真的是非常简单方便。
2 - 尝试使用YHImageClassifier模型
前面我们导出了YHImageClassifier模型,此模型可以简单的对火影忍者中的佐助或鸣人进行识别。需要注意,由于在训练时我们使用的数据量很小,因此在进行识别时,我们应尽量的选择与训练数据集类似的图片。
YHImageClassifier模型的使用和前面文章介绍的官方模型的使用没有区别,我们可以再选两张鸣人和佐助的图片(不在训练集中也不在测试集中的),Demo代码如下:
1 | import UIKit |
效果如下图所示:

提示:最好使用真机来进行模型测试,不要使用模拟器。
使用Create ML,我们可以训练处一些定制化强,非常有用的图片识别器。例如某个生产的产品是否合格,某个生成的图片是否合格等,只要有大量的数据支持,模型的预测可以非常准确。
文中涉及到的示例可以在如下地址下载:
https://github.com/ZYHshao/MachineLearnDemo
欢迎留言交流!